
1.HDFS 基本结构
分布式文件系统,高吞吐量,延迟较大, 主要结构包括namenode 和datanode节点。
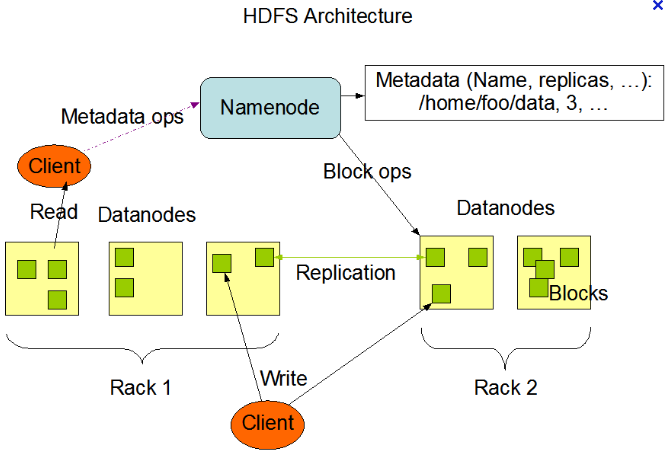
问题:
1. namenode单点故障
2. datenode 通过协议进行副本同步
3. 为解决namenode单点故障问题,增加standby节点,如何进行同步???。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。虽然不完全是个namenode的备份,更确切的是个辅助节点)周期性将元数据节点的命名控件镜像文件和修改日志合并
4. 如何进行switchover? 依靠zookeeper,一方面负责活动点选择,一方面负责错误校验。也可以用作分布式锁,具体稍后研究zookeeper。
解答:
namenode解决单点故障有两个方案,一个是利用本身提供的secondary namenode,但是有延迟,仅仅是备份,会造成数据丢失;第二种方法是同步并原子性写入本地硬盘的同时,也写入到一个NFS服务器。(NFS服务器挂掉的概率暂时不考虑)
2. HBASE
3. ZooKeeper
Zookeeper的核心是一个精简的文件系统,它的原语操作是一组丰富的构件(building block),可用于实现很多协调数据结构和协议,包括分布式队列、分布式锁和一组同级节点中的“领导者选举”(leader election)。
Zookeeper实现的是Paxos算法。Zookeeper集群启动后自动进行leader selection,投票选出一台机器作为Leader,其他的都是Follower。通过heartbeat的机制,Follower从Leader获取命令或者消息,同步自己的数据,和Leader保持一致。为了保证数据的一致性,只有当半数以上的Follower的状态和Leader成功同步了之后,才认为这次数据更新是成功的。为了选举方便,Zookeeper集群数目是奇数
参考: